Com a crescente necessidade de armazenar e processar grandes volumes de dados de maneira eficiente, os bancos de dados não relacionais, ou NoSQL, surgiram como uma alternativa flexível e escalável aos bancos de dados tradicionais.
Diferente dos bancos relacionais, que utilizam tabelas estruturadas, os bancos NoSQL trabalham com modelos mais dinâmicos, como coleções de documentos, pares chave-valor e grafos. Esse modelo de armazenamento permite um desempenho superior em aplicações que exigem alta disponibilidade e processamento rápido, como redes sociais, sistemas de recomendação e big data.
Neste texto, exploraremos os principais tipos de bancos de dados NoSQL, suas características e sua aplicação prática no dia a dia do desenvolvimento de software.
1 – O que são bancos de dados não relacionais?
Bancos de dados não relacionais, ou NoSQL, armazenam dados de forma flexível em coleções, sem utilizar tabelas relacionais. Os bancos não relacionais são conhecidos como NoSQL (Not Only SQL – Não Apenas SQL), porque não utilizam linguagem SQL para manipular seus dados.
Como comentado anteriormente, os bancos de dados NoSQL não utilizam tabelas, mas sim coleções (collections) para alocar os dados. Coleções são estruturas de dados que agrupam um número variável de itens de dados com um significado compartilhado.
Esses bancos possuem regras menos rígidas para tratar os dados e, em geral, apresentam uma performance melhor que os bancos relacionais para trabalhar com volumes massivos de dados que sofrem mudanças contínuas. Assim, eles são opções ideais para aplicações modernas que focam em mobilidade e conectividade.
O termo banco de dados não relacional foi mencionado pela primeira vez em 1998 por Carlo Strozzi, e desde então, começou a se popularizar. Durante o século XXI, grandes empresas da área de tecnologia, começaram a procurar alternativas para trabalhar com volumes gigantescos de dados de forma eficiente e os bancos não relacionais começaram a ganhar espaço, sendo hoje, uma alternativa sólida ao padrão relacional.
2 – Classificação dos bancos de dados não relacionais
Os bancos de dados não relacionais são classificados conforme a maneira que armazenam e manipulam os dados, sendo divididos em três tipos, que conheceremos nos tópicos a seguir:
2.1 – Bancos de dados de chave-valor
Esses bancos armazenam os dados em pares simples de chave-valor. Cada chave atua como um identificador exclusivo que referência diretamente o valor associado.
Esse modelo é extremamente eficiente para operações de leitura e escrita simples, tornando-o ideal para cenários que exigem desempenho elevado, como caches, sessões de usuário ou sistemas de recomendação. Possuem excelente escalabilidade horizontal e possuem uma implementação simples, embora a falta de estrutura de dados complexa possa limitar casos de uso mais sofisticados. Exemplos incluem o Redis e o DynamoDB.
2.2 – Bancos de dados de documentos
Esse tipo de banco de dados organiza suas informações em coleções de documentos, geralmente, armazenadas no formato JSON, BSON ou XML. Cada documento pode conter dados estruturados ou semiestruturados, incluindo arrays e objetos aninhados, oferecendo flexibilidade para representar estruturas complexas.
Para cada documento é atribuído um identificador único, o que facilita a recuperação rápida de dados. Esses bancos são amplamente usados em aplicativos web modernas, onde os dados exibem um formato semelhante ao JSON. Isto traz flexibilidade para esses bancos, pois permite modelar dados em um formato próximo ao que é usado na aplicação, reduzindo a necessidade de transformação. Exemplos incluem o MongoDB e o Firestore da Google Cloud Platform (GCP).
2.3 – Bancos de dados de grafos
Os bancos de dados de grafos trabalham com dados altamente interrelacionados. Ao invés de armazenar os dados em tabelas ou documentos, eles utilizam nós (nodes) para representar entidades e arestas (edges) para representar os relacionamentos entre essas entidades. Além disso, tanto os nós quanto as arestas podem conter propriedades adicionais, permitindo uma representação rica e detalhada.
Este modelo é particularmente poderoso para os casos em que os relacionamentos são tão importantes quanto os dados em si como, por exemplo, em redes sociais, recomendações personalizadas, sistemas antifraude e análise de rotas. Pense, em uma rede social, os nós podem representar usuários, e as arestas podem indicar “amigos”, “seguidores” ou “curtidas”.
Os bancos de grafos oferecem consultas altamente eficientes sobre relações complexas. Em vez de realizar múltiplos “joins” como em bancos relacionais, os bancos de grafos permitem navegar diretamente pelos relacionamentos, otimizando operações de análise de conexões. Exemplos incluem o Neo4j e o OrientDB.
3 – Bancos de dados não relacionais na prática
Como você pode perceber até aqui, os bancos de dados não relacionais (NoSQL) diferem dos bancos relacionais na forma como armazenam os dados. Eles não armazenam dados em tabelas estruturadas com colunas e linhas. Em vez disso, utilizam modelos flexíveis, como documentos JSON, pares chave-valor, grafos ou colunas amplas, dependendo do tipo de banco não relacional.
Um dos bancos NoSQL mais populares é o MongoDB, que armazena os dados no formato de documentos JSON (ou BSON, sua versão binária otimizada). No MongoDB, os principais comandos para manipulação de dados são:
- INSERT (insertOne, insertMany): Insere um ou vários documentos na coleção.
- FIND: Recupera documentos da coleção, similar ao SELECT no SQL.
- UPDATE (updateOne, updateMany): Atualiza um ou mais documentos existentes.
- DELETE (deleteOne, deleteMany): Remove um ou mais documentos de uma coleção.
Esses comandos são compatíveis com o modelo CRUD:
- CREATE: Adicionar dados com
insertOneouinsertMany. - READ: Buscar dados com
find. - UPDATE: Modificar documentos com
updateOneouupdateMany. - DELETE: Remover documentos com
deleteOneoudeleteMany.
Agora que entendemos a função de cada um desses comandos, vamos vê-los na prática utilizando o MongoDB.
3.1 – Criando uma coleção de dados
Vamos começar criando uma collection para um cadastro de livros. Se você não tem um banco de dados NoSQL instalado no seu computador, você pode usar um compilador online como o MyCompiler MongoDB para executar os comandos e testar os códigos de exemplo. O comando para criar uma collection é esse aqui:
db.createCollection('livros')O resultado do comando acima é esse aqui:
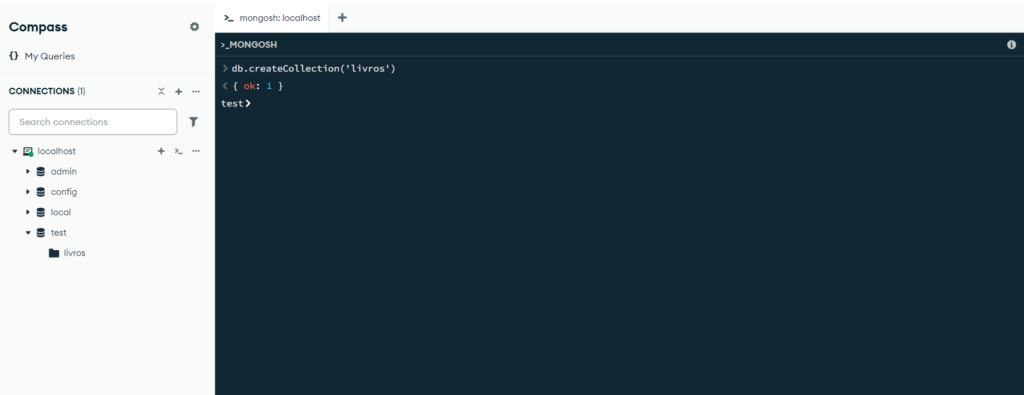
Note que ao utilizar o MongoDB instalado em uma máquina, ele criou uma base de dados chamada ‘test’ e inseriu dentro dela nossa collection chamada “livros”, a qual irá armazenar nossos dados.
3.2 – Inserindo e consultando dados na coleção
Agora vamos inserir um livro em nossa collection, usando o comando insertOne:
db.livros.insertOne([{"_id": 1, "titulo": "A Psicologia Financeira", "autor": "Morgan Housel", "ano_publicacao": 2021, "paginas": 304 }])Após, vamos executar o comando de consulta de dados:
db.livros.find()Teremos um resultado semelhante a este aqui:

Além de inserir um registro por vez, também podemos inserir vários simultaneamente com o comando insertMany:
db.Livros.insertMany([
{ "_id": 2, "titulo": "Os Segredos da Mente Milionária", "autor": "T. Harv Eker", "ano_publicacao": 2006, "paginas": 176 },
{ "_id": 3, "titulo": "1984", "autor": "George Orwell", "ano_publicacao": 2009, "paginas": 416 },
{ "_id": 4, "titulo": "A Revolução dos Bichos", "autor": "George Orwell", "ano_publicacao": 2007, "paginas": 152 },
{ "_id": 5, "titulo": "A Coragem de Ser Imperfeito", "autor": "Brené Brown", "ano_publicacao": 2016, "paginas": 208 },
{ "_id": 6, "titulo": "Hábitos Atômicos", "autor": "James Clear", "ano_publicacao": 2019, "paginas": 300 }
])Vamos executar novamente db.livros.find() para ver nossa collection atualizada:
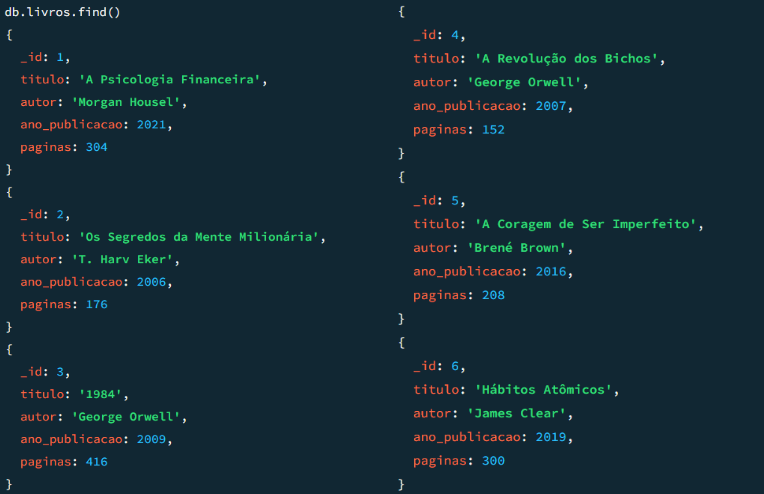
Observe que usando os comandos insertOne e insertMany conseguimos inserir os primeiros registros em nossa base. Agora vamos imaginar que queremos visualizar somente os livros que possuem mais de 300 páginas.
Para fazer essa consulta, vamos usar o comando find com os seguintes parâmetros:
db.Livros.find({ "paginas": { "$gt": 300 } })O resultado da consulta será esse aqui:

Veja que essa consulta nos trouxe dois resultados conforme nossos registros atuais. Porém, o resultado desse find deveria ter retornado três livros, pois, “Hábitos Atômicos” possui 320 páginas. Ao inserirmos os dados na collection, informamos um valor incorreto de 300 páginas. Vamos corrigi-lo:
3.3 – Atualizando dados na coleção
Para corrigir o número de páginas do livro “Hábitos Atômicos”, vamos usar o comando updateOne:
db.Livros.updateOne(
{ "_id": 6 },
{ "$set": { "paginas": 320 } }
)Agora, vamos repetir o comando db.Livros.find({ “paginas”: { “$gt”: 300 } }):

Veja que nossa correção foi eficaz e agora os dados retornados estão corretos, apresentando os três livros que possuem mais de 300 páginas.
3.4 – Excluindo dados na coleção
Para finalizar nosso exemplo baseado no modelo CRUD, vamos excluir alguns dos registros da coleção. Primeiro, vamos remover o livro “Os Segredos da Mente Milionária”, usando o comando deleteOne:
db.Livros.deleteOne({ "_id": 2 })Além da exclusão de um item por vez, também podemos excluir vários itens simultaneamente com o comando deleteMany:
db.livros.deleteMany({
"_id": { "$in": [5, 6] }
})Após a execução dos comandos, obteremos o seguinte resultado ao realizar uma nova consulta com db.livros.find():

Veja que agora, após a executação dos comandos deleteOne e deleteMany, sobraram somente três registros e os demais foram excluídos da base, conforme esperado.
Assim, concluímos nosso exemplo prático de bancos de dados não relacionais utilizando MongoDB. Note que apesar de simples, nesse exemplo conseguimos visualizar a execução do modelo CRUD, com os comandos INSERT, FIND, UPDATE e DELETE, inserindo, consultando, atualizando e excluindo registros em nossa coleção de dados.
Essas operações representam a base para trabalhar com bancos de dados não relacionais em nosso dia a dia. Embora os bancos NoSQL sejam amplamente utilizados, é importante lembrar que os bancos SQL ainda são amplamente utilizados no mercado. Para conhecer mais sobre bancos de dados relacionais clique aqui e confira este artigo!
Conclusão
Os bancos de dados não relacionais representam uma evolução significativa na forma como lidamos com dados em um mundo cada vez mais digital e conectado. Ao oferecer flexibilidade, escalabilidade e alto desempenho, eles se tornaram uma escolha essencial para diversas aplicações modernas, desde redes sociais até sistemas de análise de dados em larga escala.
O MongoDB, por exemplo, destaca-se como uma das soluções NoSQL mais populares, facilitando a manipulação de dados por meio de comandos intuitivos baseados no modelo CRUD.
Compreender e dominar bancos de dados NoSQL é um passo fundamental para profissionais que desejam se manter atualizados e preparados para os desafios do desenvolvimento de sistemas modernos e eficientes.
Espero que este artigo seja útil de alguma forma para você. Em caso de dúvidas, sugestões ou reclamações, fique à vontade para entrar em contato.