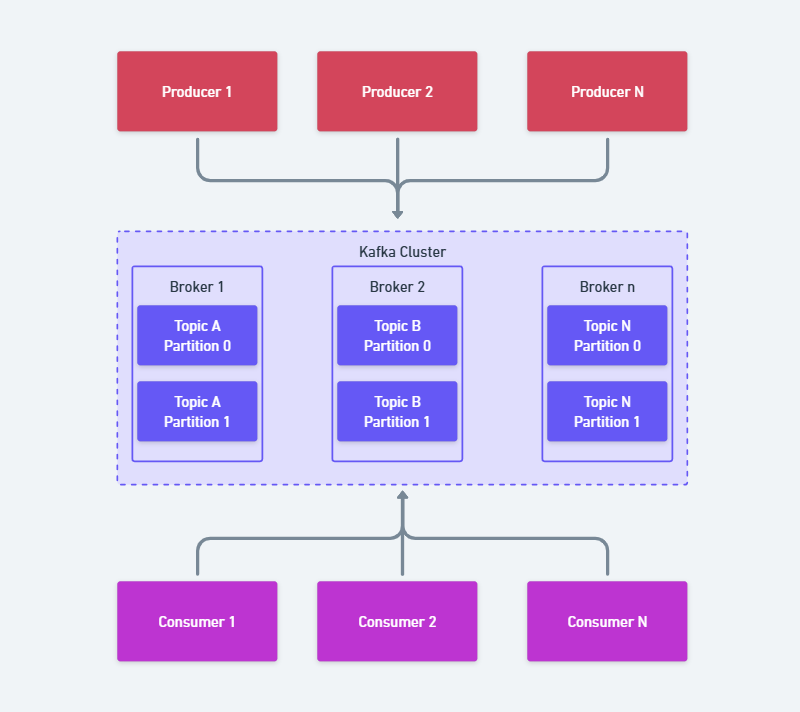
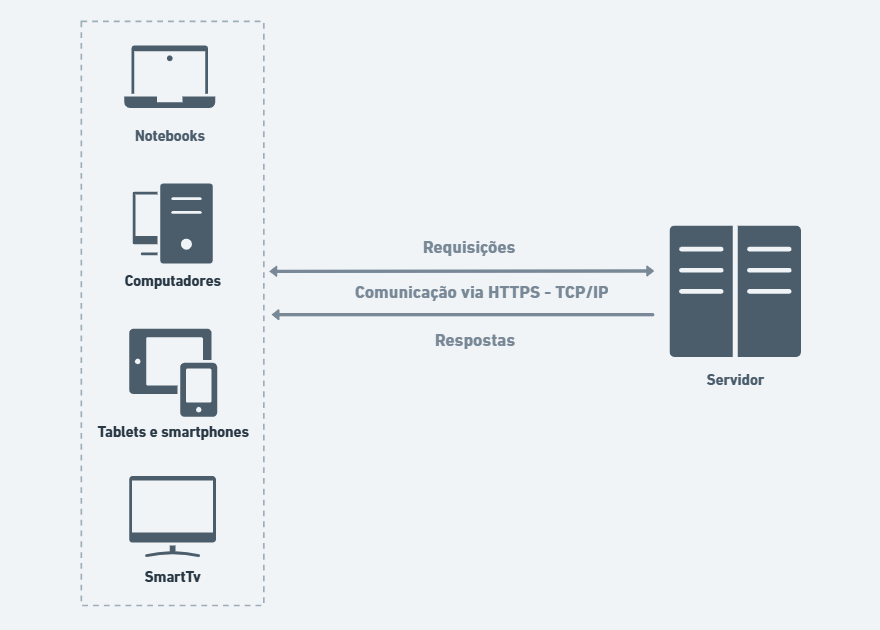
Em um cenário cada vez mais dinâmico e competitivo, empresas de tecnologia precisam entregar software com mais rapidez, qualidade e segurança. Nesse contexto, a cultura DevOps surge como uma resposta eficiente, promovendo integração entre equipes, automação de processos e melhoria contínua.
Mais do que uma prática técnica, o DevOps representa uma mudança de mentalidade, onde desenvolvimento e operações deixam de atuar de forma isolada para colaborar ativamente em todas as etapas do ciclo de vida de uma aplicação.
Neste artigo, vamos conhecer o que é DevOps, suas principais características e como colocá-lo em prática. Vamos começar?
1 – O que é DevOps?
DevOps é um conjunto de práticas que busca integrar as equipes de desenvolvimento de software (Dev) e operações de TI (Ops), com o objetivo de que trabalhem juntas de forma mais eficiente e colaborativa durante todo o ciclo de vida de um software, desde a concepção até a operação e manutenção. Em vez de equipes separadas, o DevOps promove uma mentalidade de responsabilidade compartilhada e comunicação contínua.
Mais do que ferramentas e processos, o DevOps é uma mudança cultural dentro das empresas de tecnologia — onde as barreiras entre desenvolvimento e operações são quebradas, promovendo integração, automação e melhoria contínua.
A cultura DevOps é uma abordagem que melhora a colaboração entre equipes, acelera o ciclo de entrega de software, aumenta a qualidade dos sistemas e garante maior confiabilidade nas aplicações.
1.1 – Principais características da cultura DevOps
– Colaboração e comunicação entre equipes: este é o cerne do DevOps. As equipes de desenvolvimento e operações trabalham juntas desde o planejamento até a entrega e manutenção do software. Isso significa trabalho colaborativo, comunicação aberta, feedback constante, um senso de pertencimento a um objetivo comum e o compartilhamento de informações, objetivos e responsabilidades.
– Automação de processos: a cultura DevOps proporciona a automação de tarefas repetitivas e manuais como testes, integração, deploy e monitoramento. A automação acelera os processos, reduz erros e libera as equipes para se concentrarem em tarefas mais estratégicas.
– Integração Contínua (CI) e Entrega Contínua (CD): o objetivo é entregar software de forma rápida, frequente e confiável. Isso é alcançado através de uma pipeline de integração e entrega contínua (CI/CD) responsável por automatizar as etapas de construção, testes e implantação do software.
– Infraestrutura como Código (IaC): a infraestrutura de TI (servidores, redes, armazenamento, etc.) é gerenciada e provisionada usando código, da mesma forma que o software. Isso permite versionamento, automação e repetibilidade na criação e gerenciamento da infraestrutura.
– Monitoramento e feedback contínuo: o monitoramento constante do desempenho de software e infraestrutura é essencial para identificar problemas rapidamente e garantir a estabilidade do sistema. O feedback obtido do monitoramento e das experiências dos usuários serve como fomento para melhorar continuamente o software e os processos.
– Responsabilidade compartilhada: todos são responsáveis pelo sucesso do software — da qualidade do código à estabilidade em produção.
– Cultura de aprendizado e experimentação: o DevOps incentiva uma cultura onde as equipes se sentem seguras para experimentar, aprender com os erros e implementar melhorias contínuas. A análise de falhas é vista como uma oportunidade de aprendizado, e não de culpabilização de integrantes da equipe.
2 – Como aplicar a cultura DevOps na prática
A aplicação da cultura DevOps traz diversos benefícios para empresa e departamentos de tecnologia da informação, dentre os quais podemos citar: entregas mais rápidas e frequentes; menor taxa de falhas em produção; maior estabilidade e performance dos sistemas; melhor alinhamento entre negócio e tecnologia; ambiente de trabalho mais colaborativo.
A complexidade de implementação da cultura DevOps está diretamente relacionada com fatores como tamanho da empresa ou departamento, nível de maturidade dos processos, experiências prévias da equipe, abertura para mudanças, entre outros.
2.1 – Etapas da implementação
O processo de implementação é composto pelas etapas a seguir:
1 – Comece pela Cultura
– A tecnologia é um facilitador, mas a mudança cultural é fundamental. Invista em treinamento e conscientização para que as equipes entendam os princípios do DevOps e se sintam engajadas na mudança.
2 – Promova a colaboração
– Integre as equipes de Dev e Ops em squads distintas.
– Use ferramentas de comunicação eficientes (como Slack, Teams, Jira, etc.).
– Realize cerimônias conjuntas (como daily meetings, retrospectives e plannings).
3- Implemente CI/CD
– Use ferramentas de CI/CD como Jenkins, GitHub Actions, GitLab CI, CircleCI, Azure DevOps, etc.
– Identifique as tarefas manuais e repetitivas que podem ser automatizadas. Comece com a automação de processos básicos de build, testes e deploy e, progressivamente, avance para os mais complexos.
4 – Automatize infraestrutura (IaC)
– Utilize ferramentas como Terraform, Ansible, ou AWS CloudFormation para criar e gerenciar infraestruturas de forma automatizada e versionada.
5 – Monitore tudo
– Utilize ferramentas como Prometheus, Grafana, New Relic ou Datadog para monitorar em tempo real o desempenho de serviços e aplicações. Também configure alertas para detectar problemas rapidamente.
6 – Adote práticas de observabilidade
– Centralize logs (ex: ELK Stack), use dashboards e métricas para entender o comportamento da aplicação.
7 – Fomente a cultura de aprendizado:
– Realize post-mortems sem culpabilizar ninguém.
– Compartilhe boas práticas e incentive sua aplicação pela equipe.
– Crie um ciclo de feedback. Estabeleça canais para coletar feedback dos usuários e das equipes de operações. Use esse feedback para melhorar continuamente o software e os processos.
8 – Mensure o Progresso
– Defina métricas para acompanhar o sucesso da sua implementação de DevOps. Isso pode incluir a frequência de implantações, o tempo de resposta a incidentes, a taxa de erros e a satisfação do cliente.
Conclusão
A adoção da cultura DevOps vai além da simples aplicação de ferramentas — ela requer transformação organizacional, comprometimento das equipes e uma postura contínua de aprendizado e adaptação.
Ao unir pessoas, processos e tecnologia em torno de um objetivo comum, o DevOps impulsiona a inovação, aumenta a qualidade das entregas e promove ambientes de trabalho mais integrados e eficientes.
Empresas que investem na implementação da cultura DevOps estão mais preparadas para responder rapidamente às mudanças do mercado e entregar valor real aos seus clientes.
Espero que este conteúdo seja útil de alguma forma para você. Se gostou do conteúdo, compartilhe com seus amigos e aproveite para acessar os outros artigos deste site.