Os paradigmas de programação representam diferentes estilos ou abordagens para escrever e organizar código. Cada paradigma define um modelo conceitual que influencia diretamente como problemas são analisados, como soluções são projetadas e como o software é implementado e mantido. Compreender esses paradigmas é essencial para todo desenvolvedor que deseja escrever código mais eficiente, legível e sustentável.
Neste artigo, vamos explorar os principais paradigmas de programação, suas características, exemplos e quando aplicá-los. Começamos com uma base conceitual.
1 – O que é um paradigma de programação?
Para entendermos o conceito de paradigma de programação, devemos primeiramente compreender o significado da palavra paradigma. O termo “paradigma” vem do grego paradeigma, que significa modelo ou exemplo. De acordo com o dicionário Priberam, a palavra paradigma pode ser definida como: “Algo que serve de exemplo geral ou de modelo.”
No contexto da computação, um paradigma de programação é um modelo conceitual que determina a forma de escrever códigos. Eles fornecem diretrizes sobre como estruturar algoritmos, organizar dados e controlar o fluxo de execução.
Linguagens de programação podem seguir um único paradigma (como Haskell, voltada exclusivamente ao paradigma funcional) ou ser multiparadigma, combinando diferentes abordagens (como Python e JavaScript, que suportam paradigmas imperativo, orientado a objetos e funcional).
2. Principais Paradigmas de Programação
Ao longo da evolução da computação, diversos paradigmas foram desenvolvidos para atender a diferentes demandas e contextos. A seguir, vamos conhecer os principais:
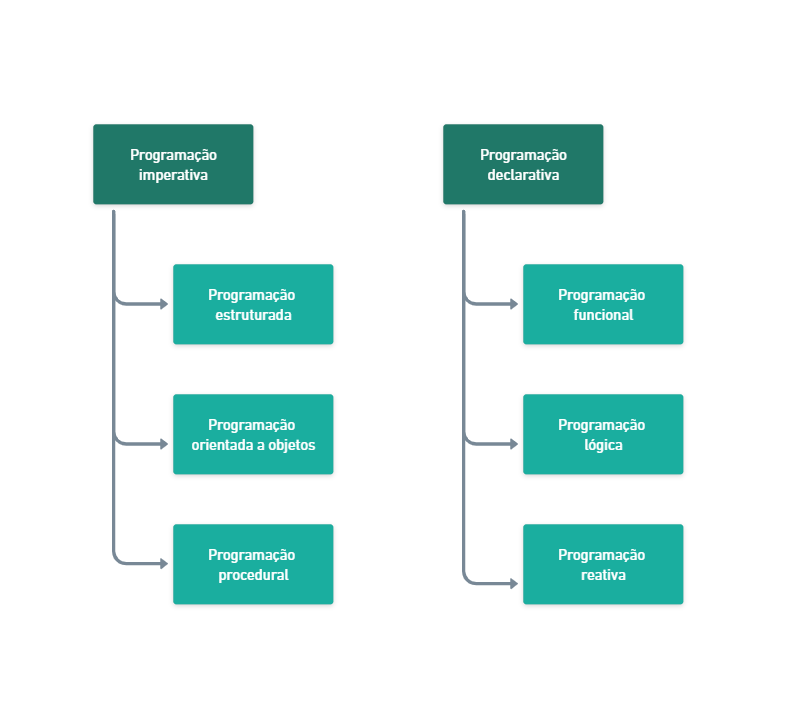
2.1 Programação imperativa
A programação imperativa é uma das formas mais tradicionais de programar. Nesse paradigma, o código é escrito como uma sequência de instruções que alteram o estado do sistema. É como dar ordens ao computador: determinando passo a passo, quais comandos ele deve executar e em qual ordem.
Características:
- Foco em como resolver o problema.
- Uso explícito de variáveis, laços e estruturas de controle.
- Controle detalhado do fluxo de execução.
Exemplos de linguagens: C, C++, Java, Python, JavaScript, PHP.
2.2 Programação declarativa
A programação declarativa é conhecida como o oposto da imperativa. Nesse paradigma, o foco recai sobre o que deve ser feito, e não em como deve ser feito. Assim, o programador descreve ao computador a sequência lógica a executar e o resultado que se espera alcançar, sem determinar o fluxo de controle. O sistema se encarrega de executar as ações necessárias para alcançar esse resultado.
Portanto, na programação declarativa, as instruções possuem uma abordagem mais generalista e não detalham exatamente cada etapa da execução.
Características:
- Abstrai o controle do fluxo de execução.
- Minimiza efeitos colaterais.
- Ideal para tarefas onde regras e resultados são mais importantes que o processo.
Exemplos: SQL, HTML, CSS, XML, Prolog.
2.3 Programação estruturada
Derivada do paradigma imperativo, a programação estruturada introduz boas práticas como a divisão do código em blocos lógicos (modularização do software) e está fundamentada no uso de estruturas básicas de controle de fluxo: sequências, decisões e repetições.
Na programação estruturada, entende-se que para resolver um problema de forma eficiente, ele deve ser quebrado em partes menores (subprogramas ou módulos). Cada uma dessas partes será responsável por resolver uma determinada fração do problema maior. Esse é o conceito de modularização de software, onde todo programa é composto por um conjunto de programas menores interconectados, chamados de módulos ou subprogramas.
Os softwares construídos com esse paradigma usam as seguintes estruturas de controle de fluxo:
– Sequências: as instruções são escritas na sequência em que serão executadas.
– Decisões/condições: blocos de código são executados somente quando determinadas condições são cumpridas. Usa-se estruturas como IF – ELSE e SWITCH – CASE.
– Repetições: blocos de código são executados várias vezes até que uma condição seja cumprida. Usa-se estruturas como FOR, WHILE e Recursividade.
Características:
- Redução de código espaguete.
- Organização por funções e blocos.
- Uso de estruturas como
if/else,switch,for,while.
Exemplos: C, C++, C#, Java, Python, PHP.
2.4 Programação procedural
Também derivada do paradigma imperativo, a programação procedural agrupa as instruções em procedimentos (também chamados de funções, métodos ou sub-rotinas). Cada procedimento realiza uma tarefa específica, promovendo modularização e reutilização de código. Esses procedimentos devem ser acionados sequencialmente, durante a execução do software.
Características:
- Organização baseada em chamadas de funções.
- Separação de responsabilidades.
- Facilidade de manutenção e testes.
Exemplos: C, C++, PHP, Python, Go.
2.5 Programação orientada a objetos (POO)
A programação orientada a objetos também deriva da programação imperativa. É o paradigma mais difundido e usado na atualidade. A POO modela o software com base em objetos do mundo real. A ideia central é replicar o mundo real através de códigos que usam classes e objetos para representar tudo aquilo que existe.
As classes são os modelos que representam coisas reais. Já os objetos são instâncias dessas classes, que encapsulam dados (atributos) e comportamentos (métodos). Esse paradigma favorece a reutilização, escalabilidade e organização do código.
Características:
- Encapsulamento, herança, polimorfismo e abstração.
- Interação entre objetos para compor o comportamento do sistema.
- Facilita a modelagem de domínios complexos.
Exemplos: Java, C++, C#, Python, Ruby, PHP.
2.6 Programação funcional
Baseada em conceitos matemáticos, a programação funcional trata funções como cidadãos de primeira classe. Ela evita estados mutáveis e prioriza funções puras — que sempre produzem o mesmo resultado para os mesmos argumentos.
Características:
- Imutabilidade e ausência de efeitos colaterais.
- Uso intensivo de funções e composição.
- Paradigma adequado para concorrência e paralelismo.
Exemplos: Haskell, Elixir, Scala, JavaScript (parcialmente), Kotlin (parcialmente).
2.7 Programação lógica
A programação lógica também deriva da programação declarativa. Ela está baseada no uso de regras e lógica formal para resolução de problemas. O programador declara fatos e regras, e o motor de inferência da linguagem deduz as conclusões.
Características:
- Usa lógica de predicados para inferir respostas.
- Muito usada em inteligência artificial e sistemas especialistas.
Exemplo: Prolog.
2.8 Programação reativa
Também derivada da programação declarativa, a programação reativa possui foco na construção de sistemas orientados a eventos e fluxo de dados assíncronos. É ideal para aplicações que exigem respostas imediatas a mudanças de estado, como interfaces gráficas e aplicações em tempo real.
Características:
- Fluxos de dados e propagação de mudanças.
- Combina bem com programação funcional e orientada a eventos.
Exemplos: RxJS, Reactor (Java), Angular (RxJS), Kotlin Flow.
3. Qual o melhor paradigma de programação?
Depois de ler este artigo, talvez você esteja se perguntando qual o melhor paradigma de programação? E a resposta é: depende. Nenhum paradigma é universalmente melhor, tudo depende do contexto. A escolha do paradigma ideal inclui fatores como:
- A natureza do problema.
- Requisitos de desempenho e manutenção.
- Equipe envolvida e conhecimento técnico.
- Linguagens e tecnologias adotadas pela organização.
Na prática, muitos projetos adotam uma abordagem híbrida, usando múltiplos paradigmas conforme a necessidade. É comum, por exemplo, combinar POO com técnicas funcionais em linguagens modernas como Python, Kotlin ou JavaScript.
Portanto, cabe aos profissionais de desenvolvimento entender os conceitos básicos de cada paradigma e usá-los de acordo com as suas necessidades.
Conclusão
Conhecer os paradigmas de programação é essencial para desenvolver software de maneira mais eficaz. Eles moldam a maneira como pensamos e resolvemos problemas computacionais.
Ao dominar diferentes paradigmas, o desenvolvedor ganha flexibilidade, capacidade analítica e autonomia para escolher a melhor abordagem para cada desafio. Lembre-se: aprender novos paradigmas amplia sua visão como desenvolvedor e contribui para um código mais limpo, sustentável e adaptável.
Espero que este conteúdo seja útil de alguma forma para você. Se gostou do conteúdo, compartilhe com seus amigos e aproveite para conhecer mais sobre programação aqui!