Com o avanço da tecnologia e o crescimento exponencial do volume de dados gerados diariamente, o Apache Kafka tornou-se em uma ferramenta essencial para lidar com esses grandes fluxos de dados de forma rápida, eficiente e escalável.
O Apache Kafka é uma das principais plataformas de streaming de eventos em tempo real da atualidade. Utilizado por grandes empresas ao redor do mundo, o Kafka permite a coleta, armazenamento, processamento e distribuição de grandes quantidades de dados, garantindo alta performance.
Neste texto, vamos explorar o que é o Apache Kafka, como ele funciona, e também demonstrar seu uso prático com um exemplo simples e didático em Python. Vamos começar?
1 – O que é o Apache Kafka?
O Apache Kafka é uma plataforma open source de streaming de eventos usada para coletar, armazenar, processar e distribuir grandes volumes de dados em tempo real. Ele é utilizado em aplicações que precisam lidar com fluxos contínuos e volumosos de informações, como logs de sistemas, monitoramento de sensores, processamento de pagamentos, atualizações de estoques e muito mais.
O Kafka foi lançado em 2011, como resultado do trabalho de um grupo de desenvolvedores do LinkedIn. Inicialmente, eles criaram a ferramenta para uso interno da própria empresa. O objetivo era desenvolver uma ferramenta para o processamento diário de grandes volumes de mensagens. Em sua primeira versão, o Kafka conseguia processar até 1,4 trilhão de mensagens por dia, um número expressivo de dados.
O código desenvolvido por Jun Rao, Jay Kreps e Neha Narkhede se tornou público ainda em 2011 e desde então começou a popularizar-se entre os desenvolvedores do mundo todo. Três anos depois, em 2014, os desenvolvedores Jun, Jay e Neha abriram uma empresa chamada Confluent, que fornece uma versão comercial do Apache Kafka.
É válido lembrar que, mesmo que existam versões comerciais do Kafka, ele é um projeto de código aberto. Inclusive, a plataforma foi doada pelos seus criadores à Apache Software Foundation (dai o nome Apacha Kafka), que a mantém até os dias atuais, incorporando novas funcionalidades e melhorias ao Kafka.
2 – Como funciona o Kafka?
O Kafka funciona como uma plataforma de mensagens, utilizando o modelo de Publicação/Assinatura (Publisher/Subscriber ou Pub/Sub). Nesse modelo, temos um produtor de informações (ou mensagens) de um lado, e um receptor do outro lado. Entre eles fica um servidor que atua como um intermediador entre as partes. Observe o esquema abaixo:
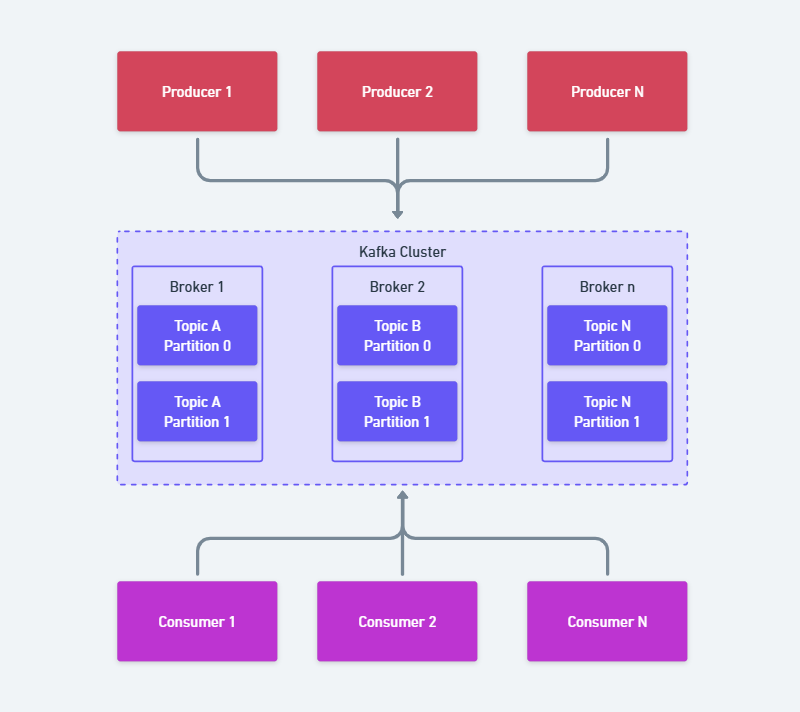
Vamos imaginar uma empresa de entregas que recebe pedidos de um e-commerce e precisa faturá-los antes de distribuí-los para os seus entregadores. No Kafka, isso funciona assim:
- Produtores (Producers) → São os geradores ou remetentes dos dados. Em nosso exemplo, trata-se do sistema de e-commerce enviando os pedidos de seus clientes.
- Tópicos (Topics) → São as “caixas de correio” onde os dados são organizados (exemplo: um tópico chamado
pedidosarmazena todas as informações de novos pedidos). - Corretores (Brokers) → São os servidores do Kafka que armazenam os dados e garantem sua entrega aos consumidores (consumers).
- Consumidores (Consumers) → São os destinatários ou receptores dos dados. Em nosso exemplo poderia ser um sistema de faturamento consumindo os pedidos para gerar notas fiscais.
Com base no exemplo acima, podemos entender que sistemas de streaming de eventos do tipo Pub/Sub possuem um emissor (Publisher) de mensagens, responsável por transmitir os dados de um ponto a outro, e um consumidor (Subscriber), que lê essas mensagens.
Os Publishers, por sua vez, não direcionam as mensagens diretamente para seus receptores. Ao invés disso, eles agrupam suas mensagens em tópicos ou filas em um broker, que é um servidor que possui a função de centralizar essas mensagens publicadas. O receptor (Subscriber) “assina” o tópico específico para receber as mensagens agrupadas.
Sempre que um Subscriber ler uma mensagem em um tópico específico, ele deverá fazer a confirmação dessa leitura, através de um processo chamado commit.
2.1 Commits
No Kafka, o processo de confirmação de leitura das mensagens é conhecido como “commit”. Ele é um processo crucial para garantir a entrega confiável dos dados aos consumidores.
Para entender esse processo devemos saber que o kafka utiliza o conceito de offsets. Cada mensagem publicada em um tópico recebe um identificador único e sequencial chamado offset, o qual representa a sua posição dentro da partição do tópico.
A confirmação de leitura (Commit) ocorrerá quando um consumidor processar uma mensagem. Esse consumidor irá informar ao Kafka o offset da última mensagem processada com sucesso. Por sua vez, o kafka irá marcar como lidas todas as mensagens até aquele offset informado. Isso evitará que, em um novo processamento de dados, as mensagens sejam lidas em duplicidade.
É importante também observar que existem dois tipos principais de confirmação de leitura:
- Confirmação automática (auto-commit): o Kafka confirma os offsets automaticamente em intervalos regulares. É mais simples de configurar, mas pode levar à perda ou duplicação de dados em caso de falhas.
- Confirmação manual (manual commit): o consumidor controla explicitamente quando os offsets são confirmados. Oferece maior controle e garante maior confiabilidade, porém exige mais código.
A confirmação de leitura garante que o sistema processe as mensagens exatamente uma vez (ou pelo menos uma vez, dependendo da configuração). Em caso de falhas, o consumidor pode retomar o processamento a partir do último offset confirmado, evitando a perda de dados.
Realizar a confirmação de leitura é fundamental para garantir a integridade e a consistência dos dados em sistemas que consomem dados de streaming de eventos.
3 – Exemplo prático
Agora que você entendeu o que é o Apache Kafka e como ele funciona, que tal ver um exemplo prático com código?
A ideia aqui é bem simples: vamos criar um produtor que enviará algumas mensagens para o Kafka com informações de vendas realizadas por alguns vendedores, e um consumidor que escuta esse tópico e imprime as mensagens recebidas.
Para isso, você vai precisar ter instalado na sua máquina:
- Ter o Apache Kafka rodando localmente: você pode usar o Docker ou instalar manualmente. Eu recomendo que você utilize o Docker, pois, ele facilita muito o processo de instalação.
- Ter o Python instalado na sua máquina e o gerenciador de pacotes pip;
- Instalar a biblioteca
kafka-python: no terminal do seu sistema operacional execute o comandopip install kafka-python.
Após instalar as ferramentas necessárias, inicie o container kafka e acesse-o com o comando docker exec -it kafka bash
Após acessar o kafka, vamos criar um tópico chamado comercial, com o seguinte comando: kafka-topics.sh --create --topic comercial --bootstrap-server localhost:9092
3.1 – Criando os códigos
Para nosso exemplo, vamos criar dois códigos: um producer e um consumer.
O primeiro arquivo que vamos criar é o producer.py, que será responsável por enviar 5 mensagens para nosso tópico do kafka:
from kafka import KafkaProducer
import json
# Cria um produtor Kafka conectado ao servidor local
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# Lista de mensagens para envio
mensagens = [
{"vendaId": "50001", "vendedor": "ana.silva", "valor": 120.50, "formaPagamento": "PIX"},
{"vendaId": "50002", "vendedor": "joao.souza", "valor": 80.00, "formaPagamento": "Crédito"},
{"vendaId": "50003", "vendedor": "maria.lima", "valor": 230.90, "formaPagamento": "Débito"},
{"vendaId": "50004", "vendedor": "carlos.pereira", "valor": 45.75, "formaPagamento": "Dinheiro"},
{"vendaId": "50005", "vendedor": "lucas.almeida", "valor": 150.00, "formaPagamento": "PIX"}
]
# Envia cada mensagem e imprime confirmação personalizada
for msg in mensagens:
future = producer.send('comercial', msg)
result = future.get(timeout=10)
print(f"Venda {msg['vendaId']} enviada com sucesso!")
producer.flush()Além do código do producer, vamos criar o arquivo consumer.py, que será responsável por ler nosso tópico de kafka:
from kafka import KafkaConsumer
import json
# Cria um consumidor Kafka que escuta o tópico 'transacoes'
consumer = KafkaConsumer(
'transacoes',
bootstrap_servers='localhost:9092',
value_deserializer=lambda m: json.loads(m.decode('utf-8')),
auto_offset_reset='earliest', # Começa a ler do início do tópico
group_id='meu-grupo' # Grupo de consumidores
)
print("Aguardando mensagens...")
for mensagem in consumer:
print(f"Mensagem recebida: {mensagem.value}")Com esses dois códigos, conseguiremos ver o funcionamento do kafka na prática. Para começar vamos executar nosso producer.py. O resultado obtido será esse aqui:
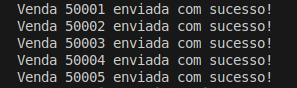
Agora que as mensagens foram enviadas para o tópico do kafka, vamos executar nosso consumer.py. O resultado será esse aqui:

Observe nesse simples exemplo que conseguimos simular o envio e consumo de algumas mensagens através do Kafka. Na prática, os sistemas que utilizam Kafka trafegam milhares ou milhões de mensagens por hora. Sem o uso de um sistema de streaming de eventos é praticamente impossível gerenciar tal volume de informação de forma eficiente. Por isso, aprender como o Kafka funciona é fundamental para profissionais e estudantes da área de TI.
Conclusão
O Apache Kafka é uma ferramenta poderosa e versátil para o processamento de dados em tempo real, oferecendo uma arquitetura robusta baseada no modelo de publicação e assinatura.
Sua capacidade de lidar com grandes volumes de mensagens de forma confiável o torna indispensável em cenários que exigem alta escalabilidade e desempenho. Através do exemplo prático apresentado, foi possível observar como produtores e consumidores interagem com tópicos no Kafka, evidenciando seu papel central em sistemas modernos de dados.
Para profissionais de tecnologia, dominar o funcionamento do Kafka é um diferencial competitivo relevante em um mercado cada vez mais orientado a dados.
Espero que este artigo seja útil de alguma forma para você. Em caso de dúvidas, sugestões ou reclamações, fique à vontade para entrar em contato.
Ah, e se você quiser conhecer mais sobre Arquitetura de Sistemas, não deixe de acessar a categoria que tenho dedicada ao assunto.